"Shader" term was introduced by Pixar in 1988 but today, we can refer to a shader as a "function" executed on the GPU (Graphic Processing Unit) available on your graphic card.
GPUs are really good to execute the "same" function in parallel versus the main processor of your computer a.k.a CPU ("Central processing unit") where it is good to execute a long series of random, branching and different code.
A basic rendering pipeline begins by ingesting what the CPU sends to the GPU divides in 2 categories:
- Data: 3d points, triangle list, textures, buffers, ...
- Commands, functions and states where they will indicate how the data should be process (e.g. render a cube far away from the camera and merge texture color with the ambient light)
GPU stages are very programmable and the 2 most common stages are "Vertex Shader" and "Pixel Shader".
The "Vertex shader" stage is where the GPU calls specific functions on every 3d point to apply some transformation (e.g. animation, position, rotation, scaling).
This is the part where you can set any 3d objects on the map at different positions.
After this state, there is a fixed stage called "Rasterizer" where it will interpolate between points that compose a triangle to "update" pixels on "screen".
During that update and for every pixel, a function (Pixel Shader) will be called.
A quick summary to resume how GPU processes at parallel level, If your monitor is 1920 by 1080 and your games runs at 60 frames per seconds,
you can expect ~125 millions of functions called every second and that only for the pixel shaders.
Usually games use multiple passes (e.g. deferred, post process, motion-blur, UI) depending of the complexity so the count should be higher.
Shadertoy doesn't use the same basic pipeline above. It focuses more on the pixel shader side where only 2 fixed triangles (or one quad) are rendered to fill the viewport and
users can customize this pixel shader function (I skipped the buffer A-D part for clarity).
The Steps
The first thing I did for the porting was to convert the pixel shader code from GPU to CPU.
It's not the same instructions between those processor units so I re-implemented some basic math functions
(e.g. dot product, vector length, interpolate function, ...).
I could use some open source library (e.g. OpenGL Mathematics / GLM) for the conversion but the pixel shader code doesn't have a lot of different math functions
and I want to keep the port small since I expect to modify the codebase a lot to fit in this tiny CPU device.
I also used one of the principles that I like from John Romero's GDC talk: "Use a superior development system than your target".
I also wrote a blog post about this GDC talk and principles.
So, I created an intermediate version on Windows that ran on CPU before to run directly on PI-Pico.
The Windows version will be useful for faster iteration and debugging.
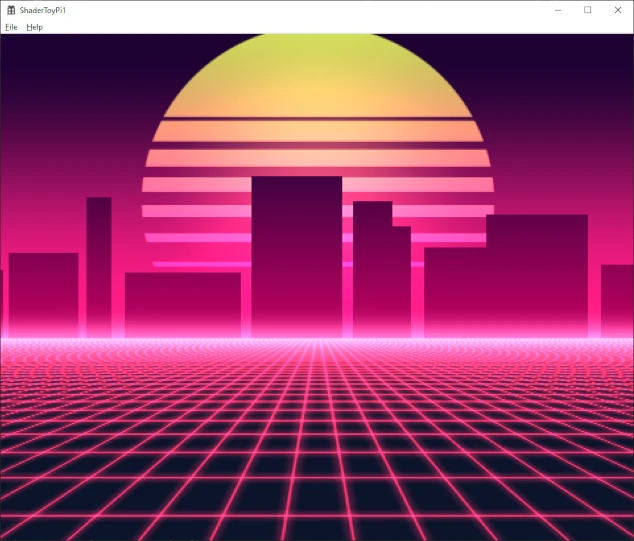
Now that I have a working version, I run it on pi-pico and here is the result:
One frame takes more than 4000 milliseconds which is 0.25 frame per seconds (fps). Usually we target to be between 30 to 60 fps (for gaming).
Quick recap for the Pi-Pico specs: No GPU, Dual ARM Cortex-M0+ at 133MHz and 264kB on-chip SRAM in six independent banks.
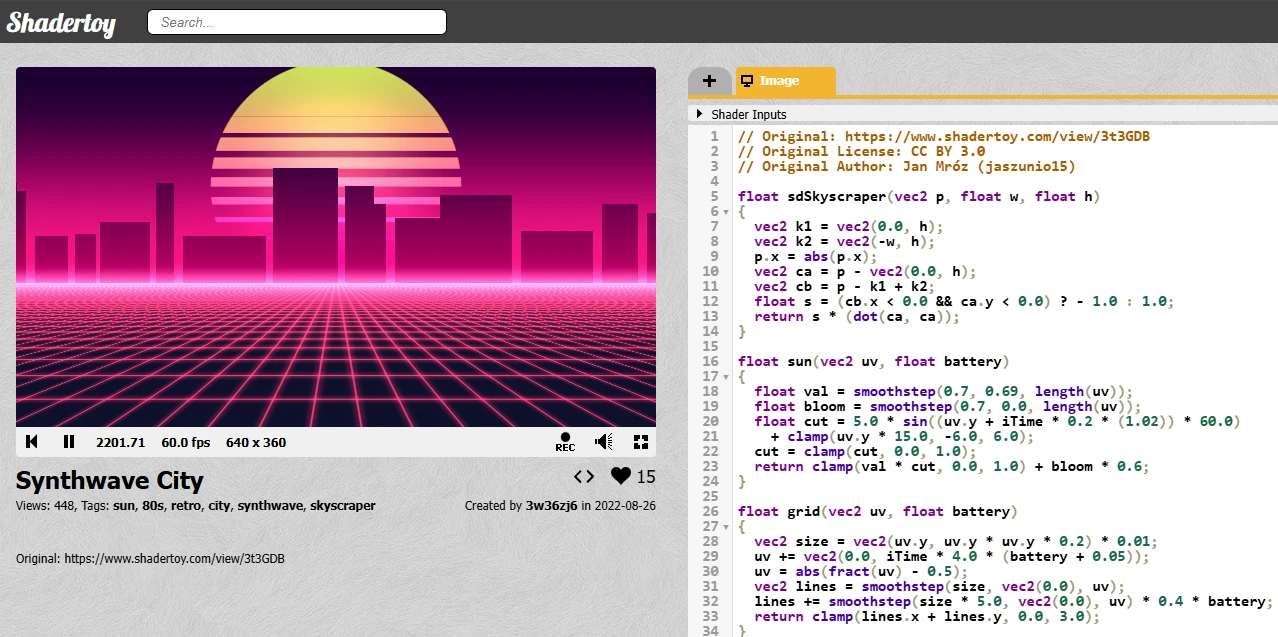
Below is the original source code on Shadertoy and you may have already found why it takes so long on Pi-Pico.
The code works well on GPU for the parallelism but it's very slow on Pi-Pico CPU.
The main reason is that every pixel computes all the "world" as buildings, background, sun, and floor.
And during this compute, it will sectorize, blend and discard to only keep what the pixel "see" which it's typical for shadertoy examples.
During the optimization pass, I did a lot of back and forth between the Windows version and the pi-pico version.
Pi-Pico is not really friendly with floating value so I converted some double (64 bits) format into float (32 bits) and later converted into fixed point
where it's a fast format (specially for ARM processor).
It took about 32 commits to get the result I want!
Result
"Sometimes, the elegant implementation is just a function. Not a method. Not a class. Not a framework. Just a function."
- John Carmack
21.5 milliseconds is the new result versus +4000 milliseconds at the beginning.
The interesting part is the cost for update is 2 milliseconds on pi-pico with the new version.
The remaining usage is spent by transferring the buffer to the screen (which could be improved).
It was fun to do and most of the optimizations that I applied were from the 90's.